Discover why custom software architecture gives businesses a resilience advantage during cloud outages by mitigating the risks of cloud outages, and how strategic consulting helps decision-makers design systems where failures become manageable disruptions.
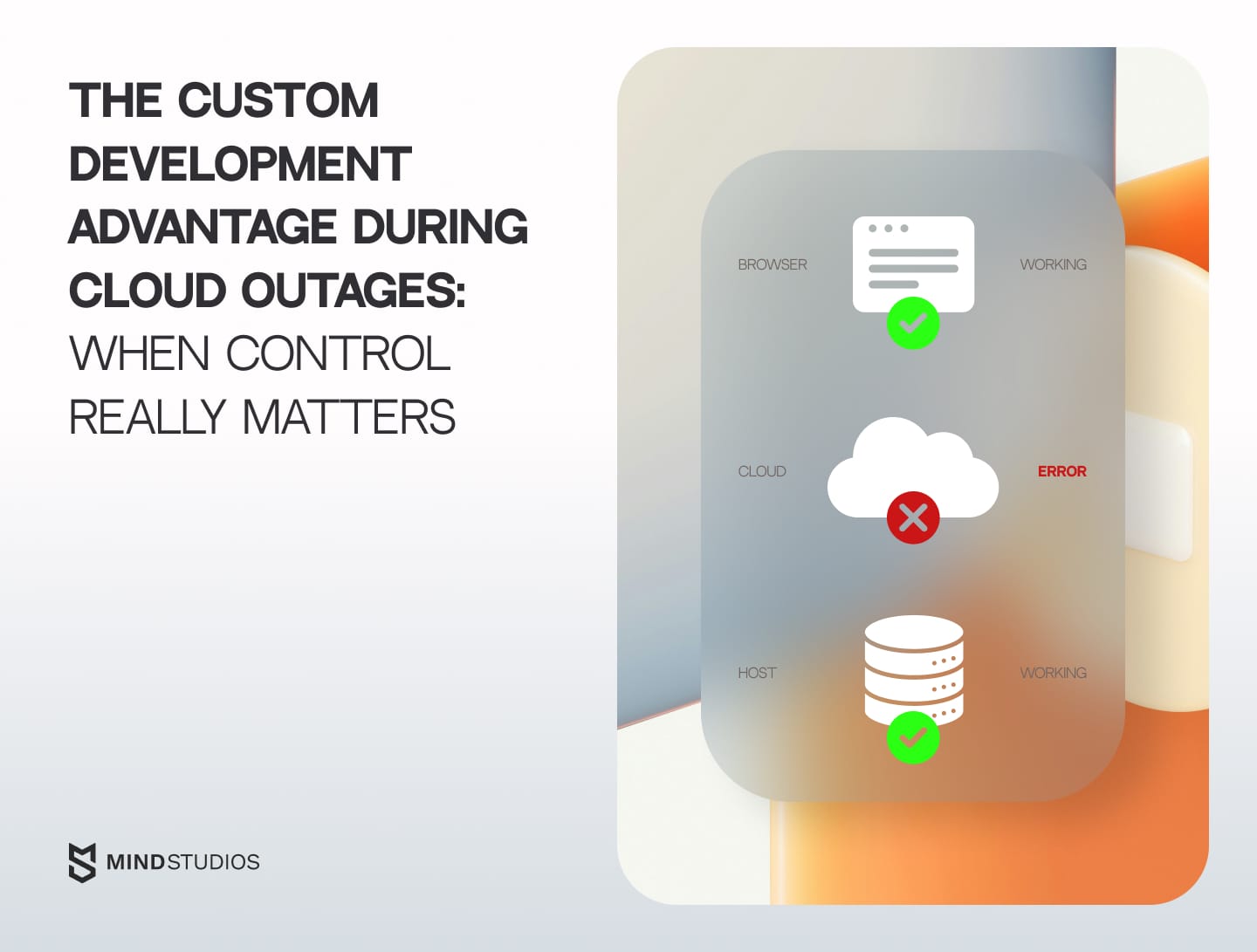
Highlights:
- AWS, Azure, and Google Cloud experienced over 100 service outages between August 2024 and 2025.
- October 2025 AWS outage affected 3,500+ companies across 60 countries for 15 hours.
- Downtime costs average $14,056 per minute, rising to $23,750 for large enterprises.
Major cloud providers go down more often than companies expect.
In October 2025, AWS went offline for 15 hours, paralyzing over 3,500 companies across 60 countries. Azure and Cloudflare experienced similar major disruptions within weeks.
For companies running logistics, fintech, marketplaces, or real estate platforms, downtime directly equals lost revenue. When payment processing stops or supply chains halt, you lose money every minute.
Today, most companies have built platforms with deep vendor dependencies. So when these services fail, they have no failover, no degraded mode, and no control over failure response.
At Mind Studios, we serve as strategic consulting partners who help technical leaders make informed architectural decisions before problems become crises. We help you understand your actual outage risk, evaluate architectural trade-offs, and design systems where failures become manageable disruptions rather than catastrophic losses.
Want to assess your cloud outage risk? Schedule a free consultation with our experts today.
Empower your project
with concrete tech
expertise
Contact Mind Studios

To design resilient systems, you need to understand exactly what fails when cloud providers go down.
Cloud providers go down more often than you think
Cloud providers promise 99.9% uptime guarantees and sophisticated redundancy systems. But the reality of 2024 and 2025 tells a different story.
Three major outages in a 60-day period demonstrate the scale of the problem. Each incident affected millions of users and caused billions in economic damage.

Mind Studios' recommendation: Start with the 15-minute test. Ask yourself: "If [your primary cloud provider] went down right now for 8 hours, which revenue-generating activities would completely stop?" If you can't answer this in 15 minutes, you don't understand your actual outage risk. Map these dependencies first, everything else is secondary.
Why modern platforms are more fragile
Modern platforms are vulnerable because of deep service dependencies. Your application likely relies on managed authentication, database services, message queues, serverless functions, API gateways, and monitoring systems. Each dependency represents a potential failure point.
Shared infrastructure amplifies the blast radius. The common causes of cloud outages are often internal configuration changes, metadata propagation issues, or DNS failures.

The business impact is substantial
Most companies discover their architectural weaknesses during outages, not during planning. We had a client convinced they were protected because they used multiple AWS availability zones. When the October 2025 outage hit, all their zones failed simultaneously because the underlying control plane went down. That's when they realized resilience means provider independence, not just redundancy within a single provider.
— says Dmytro Dobrytskyi, CEO at Mind Studios.
For businesses where every minute of downtime translates to lost revenue, the cloud outage business impact is severe:
- Average cost: $14,056 per minute;
- Large enterprises: $23,750 per minute;
- October 2025 AWS outage: $38 million to $581 million in total losses.
But the long-term consequences of cloud outages extend beyond immediate financial loss: customer trust erodes, competitive advantages disappear, regulatory scrutiny increases, and revenue-critical operations face existential risk.
What actually breaks during a cloud outage
When news reports say "the cloud was down," the reality is more complex than servers going offline.
4 critical failure points
1. Managed databases become unreachable
Your application code might run fine, but if it cannot connect to your database, your platform stops. The database service might be operational, but connectivity fails due to DNS resolution failures, authentication service disruptions, or control plane issues.
2. Authentication and identity services fail
When AWS IAM or Azure Active Directory experiences problems, your team cannot log into management consoles, your application cannot authenticate users, and your API cannot verify service-to-service calls.
3. Queues, messaging, and serverless workflows stall
When managed services for asynchronous processing fail, jobs pile up unprocessed, payment confirmations don't send, order fulfillments don't trigger, and data pipelines stop.
4. Cascading failures across dependent services
During the AWS outage, DynamoDB DNS issues prevented CloudWatch from functioning. Without monitoring data, teams couldn't diagnose problems. When Cloudflare went down in November 2025, third-party monitoring and alerting systems failed because they sat behind Cloudflare's network.

The danger of full vendor dependency
Single-cloud, single-region architectures create invisible risk. Many companies build entire platforms using one cloud provider's managed services in one geographic region. This approach is efficient but means a regional outage completely disables your business.
The architectural risks
| Risk factor | Business impact |
|---|---|
| Single-cloud dependency | Total business paralysis during provider outages. |
| Tightly coupled managed services | Cascading failures when any service experiences issues. |
| No traffic rerouting capability | Cannot redirect users to backup systems |
| No degraded mode | Binary operation: fully working or completely broken |
Mind Studios' insight: During our consulting engagements, we've seen teams architect "redundant" systems across multiple availability zones only to discover during outages that all zones share the same control plane. True redundancy means your backup systems don't depend on the same underlying infrastructure as your primary systems.

What happens when you have zero backup options
The October 2025 AWS outage lasted 15 hours. During that time, companies with single-region architectures discovered what total vendor dependency really means.
They couldn't redirect traffic. They couldn't enable fallback modes. They couldn't access their own systems to implement workarounds. They could only watch their platforms stay offline and wait for AWS engineers to resolve issues completely outside their control.
Companies with single-region architectures had zero options:
- Could not redirect users to a backup system;
- Could not enable read-only mode;
- Could not process critical transactions manually;
- Simply had to wait for AWS to resolve the issue.
When your platform goes dark for 15 hours, the costs extend far beyond the immediate downtime.
Direct costs:
- Revenue loss from downtime;
- Customer trust is damaged by repeated failures;
- Competitive disadvantage when rivals maintain availability;
- Regulatory risks when you cannot meet uptime SLAs;
- Inability to support time-critical operations.
Unsure which dependencies put your business at risk?
Our consulting team maps every managed service your platform relies on, identifies which failures would cause total business paralysis, and provides a clear roadmap for targeted resilience improvements, without requiring expensive platform rewrites. Schedule a free consultation with our experts.
Understanding the risks of vendor dependency is the first step. The next step is designing architectural strategies that reduce those risks without sacrificing the efficiency benefits of managed services.
How custom architecture improves resilience

Custom architecture means making intentional design decisions about where you need control and where managed services provide acceptable risk.
1. Decoupling critical workflows from managed services
A logistics platform might use AWS for most services but implement its own authentication layer that can fail over to a secondary provider. A fintech system might use Azure databases but maintain a read-only replica on a different infrastructure.
2. Designing provider-agnostic core components
Your business logic should not depend on AWS-specific services, Azure-specific APIs, or Google Cloud-specific implementations. Using standard interfaces means your core functionality can potentially run elsewhere if needed.
3. Selective use of managed services where failure is acceptable
Not every service requires the same level of resilience. Evaluate each managed service based on the business impact if it fails. Email notifications going down for an hour is annoying. Payment processing going down for an hour is catastrophic.
| Service type | Risk level | Recommendation |
|---|---|---|
| Email notifications | Low | Managed service acceptable |
| Data analytics pipelines | Medium | Depends on the business impact of delays |
| User authentication | High | Requires careful consideration |
| Payment processing | Critical | Custom or redundant approach |
4. Controlled degradation instead of total outage
Design your platform to maintain partial functionality when services fail. Users prefer limited access over a complete lockout.
- Marketplace: Disable new listings but keep search and checkout working;
- Real estate platform: Show cached property data instead of real-time updates;
- Supply chain system: Accept orders in a queue for later processing.
Mind Studios’ insight: Custom architecture doesn't mean avoiding cloud services. The cloud outages impact on custom development becomes clear during actual incidents: companies with custom authentication layers still served users when AWS IAM failed, while platforms with provider-agnostic data access redirected traffic to secondary databases. This isn't about distrusting cloud providers but about having options when outages happen.
Want to know how your particular business will benefit from custom development? Book a free consultation to get a detailed action plan.
Multi-cloud and hybrid approaches: when they make sense
Custom architecture gives you control over individual system components, but some businesses need resilience strategies that span multiple cloud providers.
The question is: which multi-cloud approach makes financial sense for your situation?
- Theoretical multi-cloud means running the same workload across multiple cloud providers simultaneously.
- Practical multi-cloud means designing systems that could move between providers if necessary.

The true cost of a theoretical active-active multi-cloud
True active-active multi-cloud, where every service runs redundantly across AWS, Azure, and Google Cloud, can increase infrastructure costs by 100–150%. It also requires significant engineering investment in abstraction layers, monitoring across platforms, and managing three different cloud-specific features.
For most businesses, theoretical multi-cloud exceeds what makes financial sense. A company processing $10 million in annual revenue probably cannot justify doubling infrastructure costs to protect against cloud outages that might happen once or twice a year.
Practical multi-cloud: preserving options
Your primary infrastructure runs on AWS, but your authentication service uses standard protocols that could work with any identity provider. Your data access layer abstracts away database-specific features. Your deployment processes use containerization and infrastructure-as-code tools that work across providers.
This approach costs far less than active-active redundancy while still providing migration options if needed.
Cost versus resilience: the honest calculation
Our consulting approach helps you make this calculation systematically:
- Calculate your actual downtime cost per hour;
- Research historical outage frequency for your chosen cloud provider;
- Estimate the cost of implementing multi-cloud architecture;
- Compare these numbers.
For some businesses, accepting occasional outages costs less than preventing them. For others with strict uptime requirements, the investment justifies itself.
Mind Studios’ insight: Multi-cloud is not a silver bullet. The prevalent causes of cloud outages include configuration changes, metadata propagation errors, and DNS failures. Multi-cloud architecture protects against provider-specific failures but introduces its own complexity that can itself become a source of failures if not managed carefully.
When hybrid approaches make sense
Hybrid architectures combine cloud infrastructure with on-premises or private systems. This approach makes sense when compliance requirements, data sensitivity, or legacy systems prevent moving everything to the cloud.
Our consulting engagements often reveal that hybrid architectures provide better risk-cost balance than pure cloud strategies for certain industries.
Examples:
- Real estate platform: Run public-facing website on AWS while maintaining internal property database on private infrastructure;
- Healthcare system: Use Azure for general workloads while keeping patient records in HIPAA-compliant private data centers;
- Financial services: Host customer-facing apps in the cloud while maintaining transaction processing on-premises.
Mind Studios’ insight: Through dozens of consulting engagements, we've found that hybrid architectures work best when compliance drives the decision, not resilience. If you're keeping data on-premises because regulations require it, hybrid is your only option. If you're doing it purely for uptime, a multi-region cloud is usually more cost-effective.
The Mind Studios' approach to solving architectural pitfalls
We help companies across logistics, real estate, healthcare, and other sectors assess outage risk and implement architectures that survive failures.
Our consulting methodology emphasizes strategic assessment and planning before any implementation begins. We help you make informed decisions about where resilience investments create the most business value.
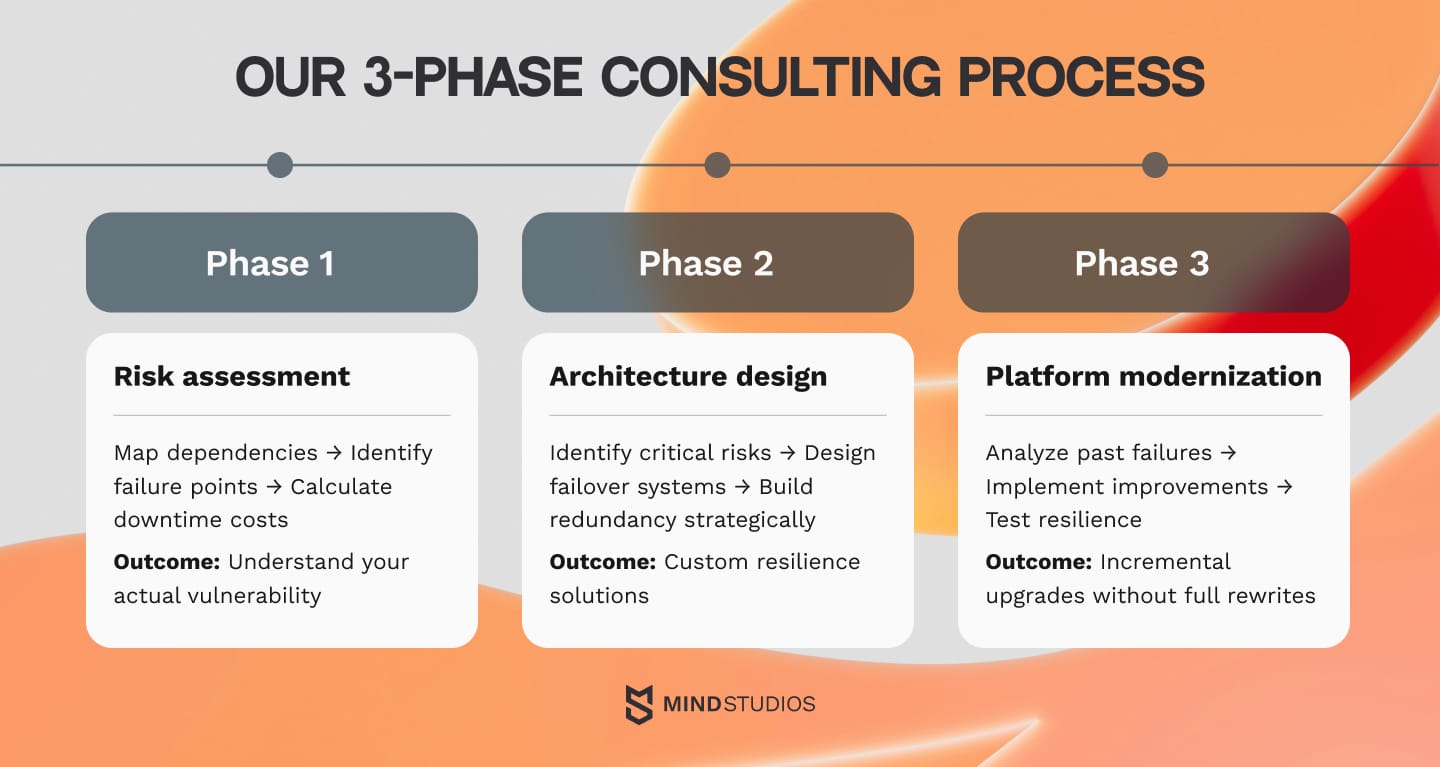
Phase #1: Cloud outage risk assessment and dependency mapping
Our consulting engagement begins with a comprehensive risk assessment. We map every managed service your platform depends on, trace how failures could cascade, identify single points of failure causing complete business paralysis, and calculate your actual downtime cost based on your revenue model.
What clients discover through our consulting: A client might believe their system has reasonable redundancy, but our analysis reveals their monitoring, alerting, authentication, and primary database all depend on the same cloud provider's control plane.
During a control plane outage, they lose visibility and access exactly when they need it most. This discovery session helps technical leaders understand their actual risk exposure before making any architectural commitments.
Mind Studios’ insight: Many companies ask us to "just start building" redundancy. We insist on assessment first. In our experience, 40% of proposed resilience investments address the wrong problems. Two weeks of consulting can save six months of building solutions that won't actually protect your business when outages happen.
Phase #2: Custom architecture design for high-availability systems
Based on our assessment findings, we provide strategic recommendations identifying specific areas where current dependencies create unacceptable business risk. Our consulting approach focuses on targeted solutions rather than expensive complete rewrites.
Examples:
- Logistics platform: We advised implementing custom authentication with failover capability, database replication to independent infrastructure, and degraded operational modes that maintain tracking and basic dispatch during cloud outages.
- Fintech platform: Our consulting recommended payment processing redundancy, transaction logging that survives cloud failures, and read-only account access during database outages.
Phase #3: Modernization of fragile cloud-native platforms
We analyze what failed during previous incidents, identify architectural changes that would have prevented or mitigated those failures, and provide actionable implementation roadmaps. Our consulting includes ongoing advisory support as you implement resilience improvements incrementally without requiring full platform rewrites.
What makes our consulting different
The cloud outage risk assessment process we use has been refined through dozens of client consulting engagements. We have seen what fails during real outages, what theoretical backup plans prove impractical under stress, and which architectural patterns actually improve survivability without creating maintenance nightmares.
We combine consulting expertise with hands-on development capability. When we recommend architectural changes, we can also implement them.
Ready to understand your risk? Book a free consultation to get answers to all your questions and learn how we can assist your business model.
Conclusion
Cloud outages increased 18% in 2024 and lasted 19% longer, affecting thousands of businesses.
The strategic question is not whether cloud outages will affect your business (because they will), but whether you've designed your architecture to fail gracefully or catastrophically.
Companies that maintained operations during major cloud outages had made strategic architectural decisions that preserved options during failure scenarios. These advantages resulted from consulting engagements where technical leaders assessed actual risk exposure and made informed decisions about where resilience investments create the most value.
Mind Studios serves as your strategic consulting partner in these critical decisions. We help you understand where your specific dependencies create unacceptable business risk, quantify what outage scenarios would cost your business, and design targeted solutions within realistic budgets.
Our consulting process starts with a comprehensive risk assessment and provides strategic recommendations that balance resilience requirements against implementation complexity and cost. Contact us to start building resilience into your architecture.